How Does an LLM Work? A Deep Dive into Large Language Models
Large Language Models (LLMs) are revolutionizing how we interact with technology. From generating text to translating languages, these powerful AI systems are rapidly changing the landscape of artificial intelligence. But how does an LLM work? This article provides a comprehensive, non-technical explanation of the inner workings of LLMs, demystifying the complex processes behind their impressive capabilities.
Understanding the Basics of LLMs
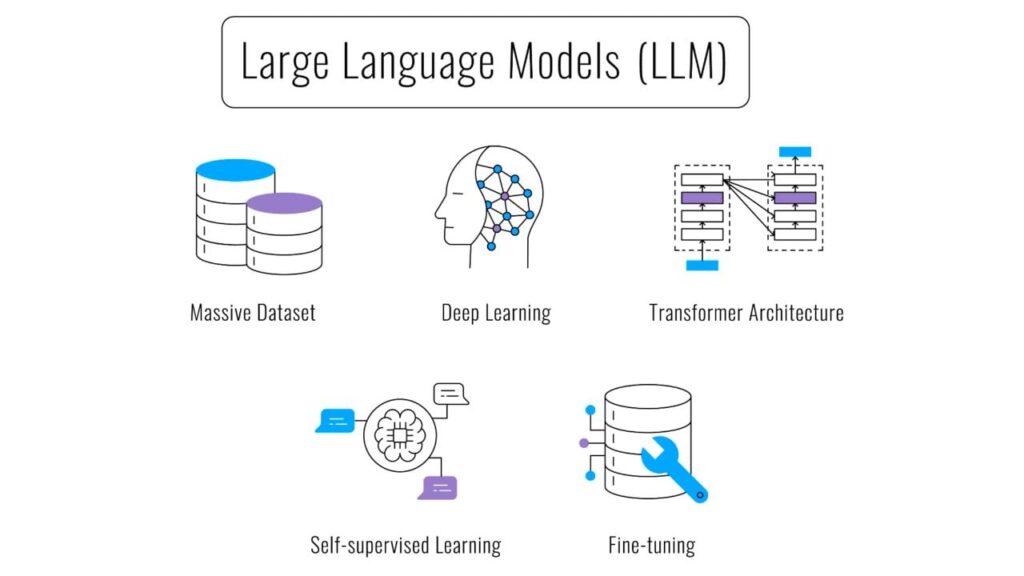
At its core, an LLM is a type of neural network designed to understand and generate human language. These models are ‘large’ because they contain billions or even trillions of parameters, which are the adjustable weights that determine how the network processes information. The more parameters, the more complex patterns the model can learn.
The primary function of an LLM is to predict the next word in a sequence. Given a string of text, the model analyzes the context and attempts to determine the most probable word that should follow. This process is repeated iteratively to generate longer pieces of text, such as articles, summaries, or even code.
The Architecture of an LLM: Transformers
The architecture that powers most modern LLMs is the Transformer. Introduced in a groundbreaking 2017 paper titled “Attention is All You Need,” the Transformer architecture replaced recurrent neural networks (RNNs) that were previously dominant in natural language processing. Transformers excel at parallel processing and can handle long-range dependencies in text more effectively.
The Attention Mechanism
A key component of the Transformer is the attention mechanism. Attention allows the model to focus on the most relevant parts of the input when making predictions. Instead of treating all words equally, the attention mechanism assigns weights to each word, indicating its importance to the current task. This enables the model to understand context and relationships between words more accurately.
Imagine reading a sentence: “The cat sat on the mat because it was comfortable.” To understand what “it” refers to, you need to pay attention to “mat.” The attention mechanism allows the LLM to do something similar, effectively highlighting the relevant words in the input sequence.
Encoder and Decoder
The Transformer architecture consists of two main parts: an encoder and a decoder. The encoder processes the input text and creates a representation of its meaning. The decoder then uses this representation to generate the output text. Some LLMs, like BERT, use only the encoder, while others, like GPT, use only the decoder. Models like T5 use both the encoder and decoder.
- Encoder: Processes the input sequence and creates a contextualized representation.
- Decoder: Generates the output sequence based on the encoder’s representation.
Training an LLM: A Massive Undertaking
Training an LLM requires a vast amount of data and computational resources. The model is fed massive datasets of text and code, and it learns to predict the next word in a sequence through a process called self-supervised learning.
Self-Supervised Learning
In self-supervised learning, the model learns from unlabeled data. The training process involves masking some of the words in the input text and asking the model to predict the missing words. This teaches the model to understand the relationships between words and the context in which they appear.
For example, given the sentence “The quick brown fox jumps over the lazy dog,” the model might be presented with “The quick brown [MASK] jumps over the lazy dog.” The model then tries to predict that the missing word is “fox.”
The Training Process
The training process is iterative. The model makes predictions, compares them to the actual words, and adjusts its parameters to improve its accuracy. This process is repeated millions or billions of times until the model achieves a satisfactory level of performance.
Training an LLM can take weeks or months, even with the most powerful hardware. The cost of training can be millions of dollars, highlighting the significant investment required to develop these models. [See also: The Environmental Impact of AI]
How Does an LLM Generate Text?
Once trained, an LLM can be used to generate new text. The process involves feeding the model a starting prompt and then iteratively predicting the next word in the sequence. The model uses its learned knowledge and the context of the prompt to generate coherent and relevant text.
Decoding Strategies
There are several strategies for decoding the output of an LLM. Some common methods include:
- Greedy Decoding: Always selects the most probable word at each step. This is simple but can lead to repetitive or uninteresting text.
- Beam Search: Keeps track of multiple possible sequences and selects the most probable sequence at the end. This can produce more diverse and coherent text than greedy decoding.
- Sampling: Randomly selects words based on their probabilities. This can generate more creative and unexpected text.
Temperature
Temperature is a parameter that controls the randomness of the output. A higher temperature makes the output more random, while a lower temperature makes it more deterministic. Adjusting the temperature can be a useful way to control the creativity and coherence of the generated text.
Applications of LLMs
LLMs have a wide range of applications across various industries. Some of the most common applications include:
- Text Generation: Writing articles, blog posts, and marketing copy.
- Translation: Translating text from one language to another.
- Summarization: Summarizing long documents or articles.
- Chatbots: Creating conversational AI agents that can answer questions and provide support.
- Code Generation: Writing code in various programming languages.
The capabilities of LLMs are constantly expanding, and new applications are emerging all the time. As these models become more powerful and accessible, they are likely to have an even greater impact on our lives. [See also: The Future of AI and its Impact on Society]
Challenges and Limitations
Despite their impressive capabilities, LLMs also have limitations. One of the main challenges is their tendency to generate incorrect or misleading information. Because they are trained on vast amounts of data, they can sometimes learn and perpetuate biases or inaccuracies present in the data.
Bias and Fairness
LLMs can exhibit biases related to gender, race, and other protected characteristics. This can lead to unfair or discriminatory outcomes. Researchers are working to develop techniques to mitigate these biases and ensure that LLMs are fair and equitable.
Hallucinations
LLMs can sometimes “hallucinate,” meaning they generate information that is not based on reality. This can be a serious problem, especially in applications where accuracy is critical. It is important to carefully evaluate the output of LLMs and verify the information they provide.
Computational Cost
Training and running LLMs requires significant computational resources. This limits access to these models and can make it difficult for smaller organizations to develop and deploy them. Efforts are underway to develop more efficient LLMs that can run on less powerful hardware.
The Future of LLMs
The field of LLMs is rapidly evolving. Researchers are constantly developing new architectures, training techniques, and applications. As LLMs become more powerful and sophisticated, they are likely to play an even greater role in our lives.
One of the key areas of research is improving the ability of LLMs to understand and reason about the world. This involves developing models that can not only generate text but also understand its meaning and implications. Another area of focus is reducing the computational cost of training and running LLMs, making them more accessible to a wider range of users.
In conclusion, understanding how does an LLM work involves grasping the core concepts of neural networks, the Transformer architecture, and the training process. While challenges remain, the potential of LLMs to transform various industries is undeniable. As technology advances, we can anticipate even more innovative applications and improvements in the capabilities of these powerful language models. The future of LLMs is bright, promising a world where human-computer interaction is more seamless and intuitive than ever before. Further advancements will likely address current limitations, such as bias and the tendency to ‘hallucinate,’ ensuring that these models are not only powerful but also reliable and ethical tools. Understanding how does an LLM work is crucial for anyone looking to leverage this technology or stay informed about the future of AI.
