Exploring the Diverse World: Types of Machine Learning Models
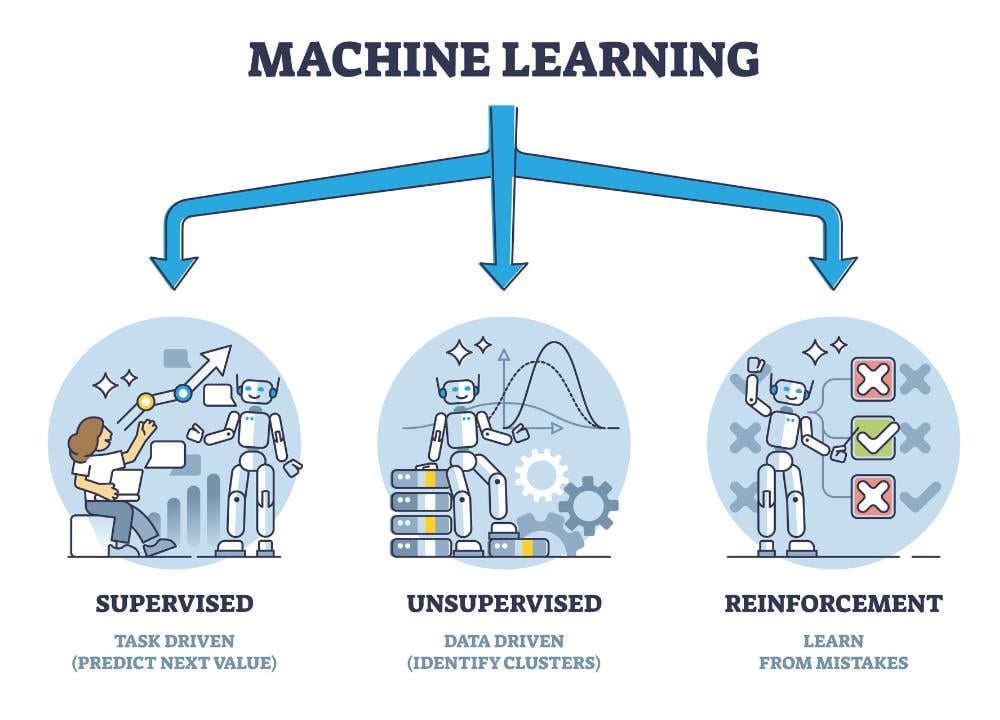
Machine learning, a cornerstone of modern artificial intelligence, has permeated countless aspects of our lives, from personalized recommendations to self-driving cars. At its core, machine learning involves training algorithms to learn from data and make predictions or decisions without explicit programming. The effectiveness of a machine learning system hinges significantly on the type of model employed. Understanding the different types of machine learning models is crucial for anyone venturing into this exciting field. This article will delve into the major categories and explore some popular examples within each.
Supervised Learning: Learning from Labeled Data
Supervised learning is perhaps the most widely used type of machine learning. In this paradigm, the algorithm learns from a labeled dataset, where each data point is paired with a corresponding output or target variable. The goal is to learn a mapping function that can accurately predict the output for new, unseen data. Common applications include classification and regression.
Classification
Classification models are used to predict categorical outcomes. For example, classifying emails as spam or not spam, or identifying the species of a flower based on its features. The model learns to assign data points to predefined classes.
- Logistic Regression: Despite its name, logistic regression is a classification algorithm. It models the probability of a data point belonging to a particular class using a sigmoid function. It’s widely used for binary classification problems.
- Support Vector Machines (SVM): SVMs aim to find the optimal hyperplane that separates data points belonging to different classes with the largest possible margin. They are effective in high-dimensional spaces.
- Decision Trees: Decision trees create a tree-like structure to make predictions. Each node in the tree represents a feature, and each branch represents a decision rule. They are easy to interpret and visualize.
- Random Forest: Random forests are an ensemble learning method that combines multiple decision trees to improve accuracy and reduce overfitting. They are robust and widely applicable.
- Naive Bayes: Naive Bayes classifiers are based on Bayes’ theorem and assume that features are independent of each other. They are computationally efficient and often used for text classification.
Regression
Regression models are used to predict continuous numerical values. For example, predicting the price of a house based on its size and location, or forecasting stock prices.
- Linear Regression: Linear regression models the relationship between the input features and the output variable as a linear equation. It’s a simple and interpretable model.
- Polynomial Regression: Polynomial regression extends linear regression by allowing for non-linear relationships between the input features and the output variable using polynomial terms.
- Support Vector Regression (SVR): SVR uses support vector machines to predict continuous values. It aims to find a function that approximates the output variable within a certain margin of error.
- Decision Tree Regression: Similar to decision tree classifiers, decision tree regression uses a tree-like structure to predict continuous values.
- Random Forest Regression: An ensemble method that combines multiple decision tree regressors to improve prediction accuracy.
Unsupervised Learning: Discovering Hidden Patterns
Unsupervised learning deals with unlabeled data, where the algorithm must discover patterns and structures without any prior knowledge of the output. Common applications include clustering and dimensionality reduction. These types of machine learning models excel at finding hidden relationships within data.
Clustering
Clustering algorithms group similar data points together based on their features. The goal is to identify distinct clusters within the data.
- K-Means Clustering: K-means aims to partition data points into k clusters, where each data point belongs to the cluster with the nearest mean (centroid). It’s a simple and efficient algorithm.
- Hierarchical Clustering: Hierarchical clustering builds a hierarchy of clusters, starting with each data point as its own cluster and then iteratively merging the closest clusters until a single cluster remains.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): DBSCAN identifies clusters based on the density of data points. It can discover clusters of arbitrary shapes and is robust to noise.
Dimensionality Reduction
Dimensionality reduction techniques reduce the number of features in a dataset while preserving its essential information. This can help to simplify models, reduce computational cost, and improve performance.
- Principal Component Analysis (PCA): PCA identifies the principal components of the data, which are the directions of maximum variance. It projects the data onto a lower-dimensional subspace spanned by these components.
- t-distributed Stochastic Neighbor Embedding (t-SNE): t-SNE is a non-linear dimensionality reduction technique that is particularly effective at visualizing high-dimensional data in low dimensions.
Semi-Supervised Learning: Bridging the Gap
Semi-supervised learning combines aspects of both supervised and unsupervised learning. It uses a dataset that contains both labeled and unlabeled data. This approach can be useful when labeling data is expensive or time-consuming. These types of machine learning models leverage both labeled and unlabeled data for training.
Semi-supervised learning algorithms can leverage the unlabeled data to improve the accuracy of the model, especially when the amount of labeled data is limited. Common techniques include self-training and co-training.
Reinforcement Learning: Learning Through Interaction
Reinforcement learning (RL) is a type of machine learning where an agent learns to make decisions in an environment to maximize a reward. The agent interacts with the environment, receives feedback in the form of rewards or penalties, and learns to adjust its actions accordingly. This is one of the more complex types of machine learning models.
RL is widely used in robotics, game playing, and control systems. Common algorithms include Q-learning and Deep Q-Networks (DQN).
Deep Learning: The Power of Neural Networks
Deep learning is a subfield of machine learning that uses artificial neural networks with multiple layers (deep neural networks) to learn complex patterns from data. Deep learning models have achieved remarkable success in various applications, including image recognition, natural language processing, and speech recognition. Understanding the different types of machine learning models within deep learning is essential for specialized applications.
Convolutional Neural Networks (CNNs)
CNNs are particularly well-suited for processing image and video data. They use convolutional layers to automatically learn spatial hierarchies of features.
Recurrent Neural Networks (RNNs)
RNNs are designed to handle sequential data, such as text and time series. They have recurrent connections that allow them to maintain a memory of past inputs.
Transformers
Transformers are a type of neural network architecture that has revolutionized natural language processing. They use attention mechanisms to weigh the importance of different parts of the input sequence. [See also: Understanding Transformer Networks]
Choosing the Right Model
Selecting the appropriate types of machine learning models depends heavily on the specific problem, the available data, and the desired outcome. Consider the following factors:
- Type of data: Is the data labeled or unlabeled? Is it numerical, categorical, or sequential?
- Problem type: Is it a classification, regression, clustering, or reinforcement learning problem?
- Desired accuracy: How accurate does the model need to be?
- Interpretability: How important is it to understand how the model makes its predictions?
- Computational resources: How much computational power is available?
Experimentation and evaluation are key to finding the best model for a given task. It’s important to try different models and evaluate their performance using appropriate metrics.
Conclusion
The world of machine learning is vast and constantly evolving. Understanding the different types of machine learning models is essential for anyone looking to apply these powerful techniques to solve real-world problems. From supervised learning to deep learning, each model has its strengths and weaknesses, and the key to success lies in choosing the right model for the right task. By carefully considering the factors discussed in this article, you can navigate the landscape of machine learning models and unlock their full potential. The diverse types of machine learning models offer solutions for a wide array of challenges, making this a field ripe with opportunity. The different types of machine learning models are constantly being refined and new models are emerging, so continuous learning and adaptation are critical for success in this dynamic field. Exploring different types of machine learning models is a journey that can lead to innovative solutions and groundbreaking discoveries. The future of AI depends on our ability to understand and effectively utilize these types of machine learning models. Mastering the nuances of these types of machine learning models is a valuable skill in today’s data-driven world. The continued development of various types of machine learning models promises to transform industries and improve lives. Recognizing the capabilities of diverse types of machine learning models is essential for leveraging the power of AI. The evolution of types of machine learning models continues to drive innovation across various sectors. Understanding the nuances of different types of machine learning models allows for more effective problem-solving. The strategic application of various types of machine learning models can lead to significant advancements in technology and research.
