Data Drifting: Understanding, Detecting, and Mitigating the Silent Killer of Machine Learning Models
In the rapidly evolving landscape of artificial intelligence and machine learning, maintaining the accuracy and reliability of deployed models is paramount. One of the most insidious threats to model performance is data drifting, a phenomenon where the statistical properties of the target variable, features, or relationships between them change over time. This article delves into the intricacies of data drifting, exploring its causes, consequences, detection methods, and mitigation strategies.
What is Data Drifting?
Data drifting, also known as concept drift or model drift, occurs when the data used to train a machine learning model no longer accurately reflects the data the model encounters in the real world. In simpler terms, the rules of the game have changed, but the model is still playing by the old rules. This discrepancy can lead to a significant degradation in model performance, rendering it unreliable and potentially causing costly errors.
Imagine a model trained to predict customer churn based on historical data. If a new competitor enters the market, or if there’s a significant shift in consumer preferences due to an external event like a pandemic, the factors driving churn might change drastically. The model, still relying on outdated patterns, will likely fail to accurately predict churn in the new environment. This is a classic example of data drifting.
Types of Data Drifting
Data drifting can manifest in several forms, each requiring different detection and mitigation techniques:
- Covariate Drift (Feature Drift): This occurs when the distribution of input features changes. For example, if a model trained on data from a specific geographic region is deployed in another region with different demographic characteristics, the input features (e.g., age, income, education level) might exhibit covariate drift.
- Concept Drift: This refers to changes in the relationship between the input features and the target variable. The underlying concept the model is trying to learn evolves over time. The churn example provided earlier is an example of concept drift.
- Target Drift: This occurs when the distribution of the target variable changes. For example, if a model is predicting fraud, and the overall rate of fraudulent transactions increases due to new scams, the target variable (fraudulent vs. non-fraudulent) will experience target drift.
Causes of Data Drifting
Understanding the causes of data drifting is crucial for proactively addressing it. Several factors can contribute to this phenomenon:
- External Events: Economic recessions, pandemics, policy changes, and natural disasters can all trigger significant shifts in data patterns.
- Seasonal Variations: Many business processes exhibit seasonal trends. For example, retail sales fluctuate throughout the year, with peaks during holidays.
- Changes in Customer Behavior: Evolving customer preferences, adoption of new technologies, and competitive pressures can all influence customer behavior and lead to data drift.
- Data Quality Issues: Changes in data collection processes, data entry errors, and missing data can introduce artificial drift into the data.
- System Updates: Changes in software, hardware, or APIs can alter the way data is generated and processed, leading to drift.
Consequences of Unaddressed Data Drifting
Ignoring data drifting can have serious consequences for businesses:
- Reduced Model Accuracy: The primary consequence is a decline in the model’s ability to make accurate predictions. This can lead to incorrect decisions and suboptimal outcomes.
- Increased Costs: Inaccurate predictions can result in financial losses, wasted resources, and increased operational costs.
- Damaged Reputation: Poor model performance can erode customer trust and damage a company’s reputation.
- Regulatory Compliance Issues: In some industries, inaccurate models can lead to non-compliance with regulations, resulting in fines and penalties.
Detecting Data Drifting
Early detection of data drifting is essential for mitigating its impact. Several techniques can be employed to monitor model performance and detect drift:
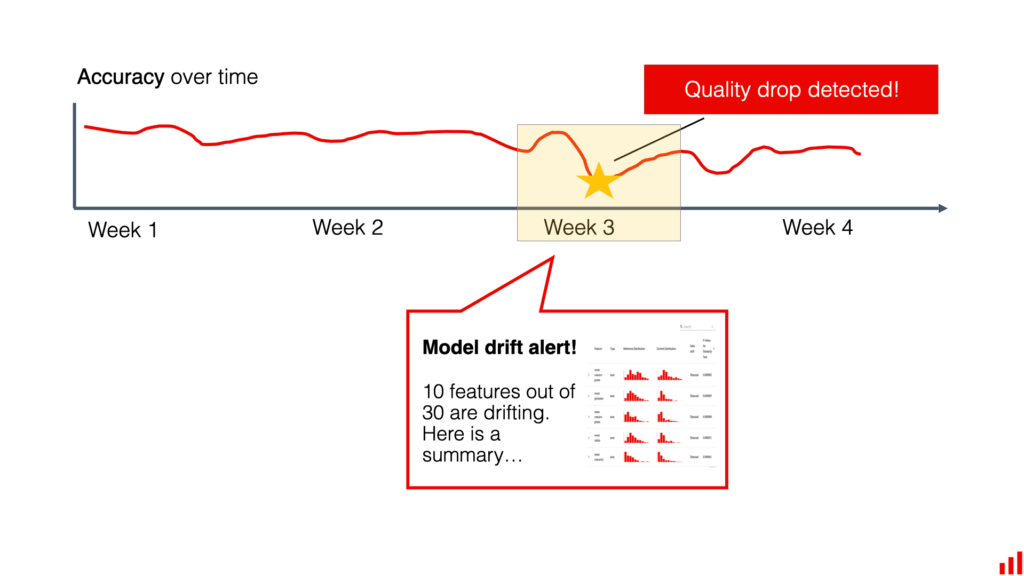
- Performance Monitoring: Continuously track key performance metrics such as accuracy, precision, recall, and F1-score. A significant drop in these metrics can indicate data drift.
- Statistical Tests: Use statistical tests such as the Kolmogorov-Smirnov test, Chi-squared test, and Mann-Whitney U test to compare the distributions of features and target variables over time. Significant differences can signal drift.
- Drift Detection Algorithms: Employ dedicated drift detection algorithms such as the Drift Detection Method (DDM), Early Drift Detection Method (EDDM), and Page-Hinkley test. These algorithms are designed to detect changes in data streams.
- Visual Inspection: Plotting the distributions of features and target variables over time can reveal visual patterns that indicate drift.
- Explainable AI (XAI) Techniques: Utilize XAI methods to understand which features are most important for the model’s predictions. Changes in feature importance can suggest that the underlying relationships between features and the target variable have shifted.
Mitigating Data Drifting
Once data drifting is detected, several strategies can be employed to mitigate its effects:
- Retraining the Model: The most common approach is to retrain the model using more recent data that reflects the current environment. The frequency of retraining should be determined based on the rate of drift and the cost of retraining.
- Adaptive Learning: Implement adaptive learning techniques that allow the model to continuously update its parameters as new data becomes available. This can help the model adapt to changing data patterns in real-time.
- Ensemble Methods: Use ensemble methods that combine multiple models trained on different time periods or different subsets of the data. This can help to improve the model’s robustness to drift.
- Feature Engineering: Re-evaluate the features used in the model and consider adding new features that are more relevant to the current environment.
- Data Augmentation: Augment the training data with synthetic data that reflects the current environment. This can help to improve the model’s generalization ability.
- Model Monitoring and Alerting: Set up a robust monitoring system that continuously tracks model performance and alerts you when drift is detected. This allows you to take proactive steps to mitigate the impact of drift.
Tools and Technologies for Data Drifting Detection and Mitigation
Several tools and technologies can assist in the detection and mitigation of data drifting:
- MLOps Platforms: MLOps platforms such as Kubeflow, MLflow, and SageMaker provide comprehensive tools for monitoring model performance, detecting drift, and automating retraining workflows.
- Data Monitoring Libraries: Libraries such as Evidently AI, Great Expectations, and TensorFlow Data Validation offer functionalities for data profiling, data validation, and drift detection.
- Cloud-Based Machine Learning Services: Cloud providers like AWS, Azure, and Google Cloud offer managed machine learning services that include built-in drift detection capabilities.
- Custom Solutions: Organizations can also develop custom solutions for drift detection and mitigation based on their specific needs and requirements.
Best Practices for Managing Data Drifting
To effectively manage data drifting, organizations should adopt the following best practices:
- Establish a Robust Monitoring System: Implement a comprehensive monitoring system that continuously tracks model performance and detects drift.
- Define Clear Metrics: Define clear metrics for measuring model performance and drift. These metrics should be aligned with the business objectives.
- Automate Retraining Workflows: Automate the process of retraining models when drift is detected. This ensures that models are always up-to-date and performing optimally.
- Document Data Lineage: Maintain a clear record of the data used to train and evaluate models. This helps to identify the root causes of drift.
- Collaborate Across Teams: Foster collaboration between data scientists, engineers, and business stakeholders. This ensures that everyone is aware of the risks of drift and is working together to mitigate them.
- Regularly Review and Update Models: Models should be regularly reviewed and updated to ensure that they are still relevant and accurate.
The Future of Data Drifting Management
As machine learning becomes increasingly integrated into business processes, the importance of managing data drifting will only grow. Future advancements in this area are likely to include:
- More Sophisticated Drift Detection Algorithms: Development of more advanced algorithms that can detect subtle forms of drift and predict future drift patterns.
- Automated Mitigation Strategies: Development of automated mitigation strategies that can automatically adapt models to changing data patterns.
- Integration with Explainable AI: Integration of drift detection with explainable AI techniques to provide deeper insights into the causes of drift.
- Real-Time Drift Detection: Development of real-time drift detection systems that can identify drift as it occurs.
In conclusion, data drifting is a significant challenge in machine learning that can have serious consequences if left unaddressed. By understanding the causes and types of drift, implementing robust detection methods, and employing effective mitigation strategies, organizations can ensure that their models remain accurate and reliable over time. The key is to proactively monitor model performance, adapt to changing data patterns, and continuously improve the model to maintain its effectiveness in the long run. [See also: Model Monitoring Best Practices], [See also: Continuous Integration for Machine Learning], [See also: Explainable AI for Model Debugging]
